


.webp)


Blog
Insights & updates from our experts
Resolve issues quickly with an AI-powered system that automates ticketing.

Resolve issues quickly with an AI-powered system that automates ticketing.

Resolve issues quickly with an AI-powered system that automates ticketing.

Resolve issues quickly with an AI-powered system that automates ticketing.
Resolve issues quickly with an AI-powered system that automates ticketing.

Resolve issues quickly with an AI-powered system that automates ticketing.

Simplify on-call scheduling, automate escalations, and reduce burnout.

Automate postmortems, AI summaries, and post-incident workflows

We're here to help

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is

The integration with Atlassian Jira using the Xurrent Integration Service is
Resolve issues quickly with an AI-powered system that automates ticketing.
Resolve issues quickly with an AI-powered system that automates ticketing.
Simplify on-call scheduling, automate escalations, and reduce burnout.
Automate postmortems, AI summaries, and post-incident workflows
Resolve issues quickly with an AI-powered system that automates ticketing.
Resolve issues quickly with an AI-powered system that automates ticketing.
Resolve issues quickly with an AI-powered system that automates ticketing.
Resolve issues quickly with an AI-powered system that automates ticketing.

We are here to help 24/7

Connect with other Xurrent Users

Get insights and tips on how to get the most out of Xurrent

Apps, APIs, and updates

Xurrent service functionality
Eliminate manual tasks, optimize workflows, and deliver faster resolutions.
Learn how organizations have reduced downtime, improved 50% MTTA & MTTR, and cut costs with Xurrent IMR.
Discover Xurrent IMR's quick support, bidirectional integrations with Jira and Slack, and more cohesive incident response capabilities compared to Opsgenie.
Understand why users value Xurrent IMR for its intuitive interface, efficient incident alerting, customizable On-call schedules, and escalations.

Every SRE team I know has invested in monitoring. Good alerting, multiple integrations, dashboards that look impressive in all-hands meetings. And most of them still have the same problem: when something fires at 2am, the first few minutes are spent figuring out whose problem it is.
That confusion, quiet and usually untracked, is where incident response actually breaks down. Not in the debugging. Not in the fix. In the handshake that should take zero seconds and instead takes ten minutes.
I've spent a lot of time thinking about why this happens even in technically mature teams, and the answer is usually the same: the structure that should exist around an incident is implicit instead of enforced. Everyone roughly knows who to call. Nobody has made that knowledge automatic.
The structure that should exist around an incident is implicit instead of enforced. That is where response actually breaks down.
There's a tendency to frame unclear ownership as a people issue: unclear communication, lack of accountability, teams that haven't gelled. In my experience, that's almost never the root cause. The root cause is that the system allows ambiguity to exist.
When an incident fires, there should be exactly one name attached to it. Not a team. A person. And that person should know they're on-call before the alert fires, not after they receive a Slack message asking if they're available.
This isn't a new idea. But there's a gap between knowing it and making it structurally impossible to violate. The moment you make escalation automatic, the moment the system calls the next person rather than waiting for someone to manually decide whether to escalate, you've removed a class of delays that look small in isolation and compound into serious MTTA problems over time.
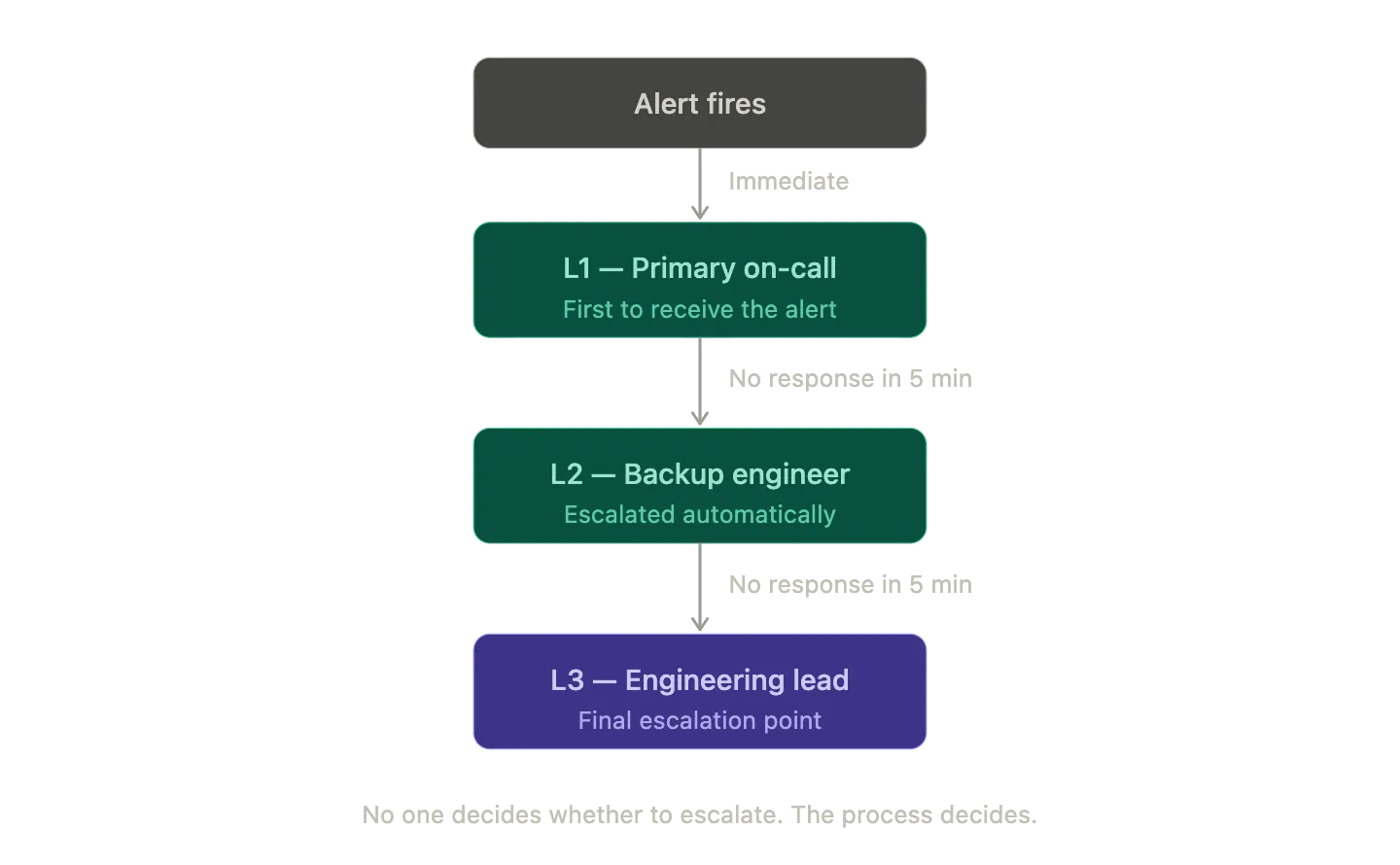
Clear ownership doesn't just improve response speed. It reduces cognitive overhead for everyone not on-call, who no longer need to monitor the situation to see if someone is handling it.
These two metrics get lumped together constantly, and it causes teams to apply the wrong fix.
When MTTA trends upward, the question to ask is structural: is the alert reaching the right person? Is the on-call rotation balanced? Is alert volume high enough that engineers have started triaging instead of responding? MTTA problems are almost always routing and ownership problems in disguise.
MTTR is different. Slow resolution usually points to one of two things: either the knowledge needed to fix the issue isn't immediately accessible, or the incident has cascading complexity that requires judgment no documentation can fully substitute for. The first is solvable with good runbooks. The second requires a team that has space to actually think, which is only possible when the process overhead of the incident itself has been automated away.
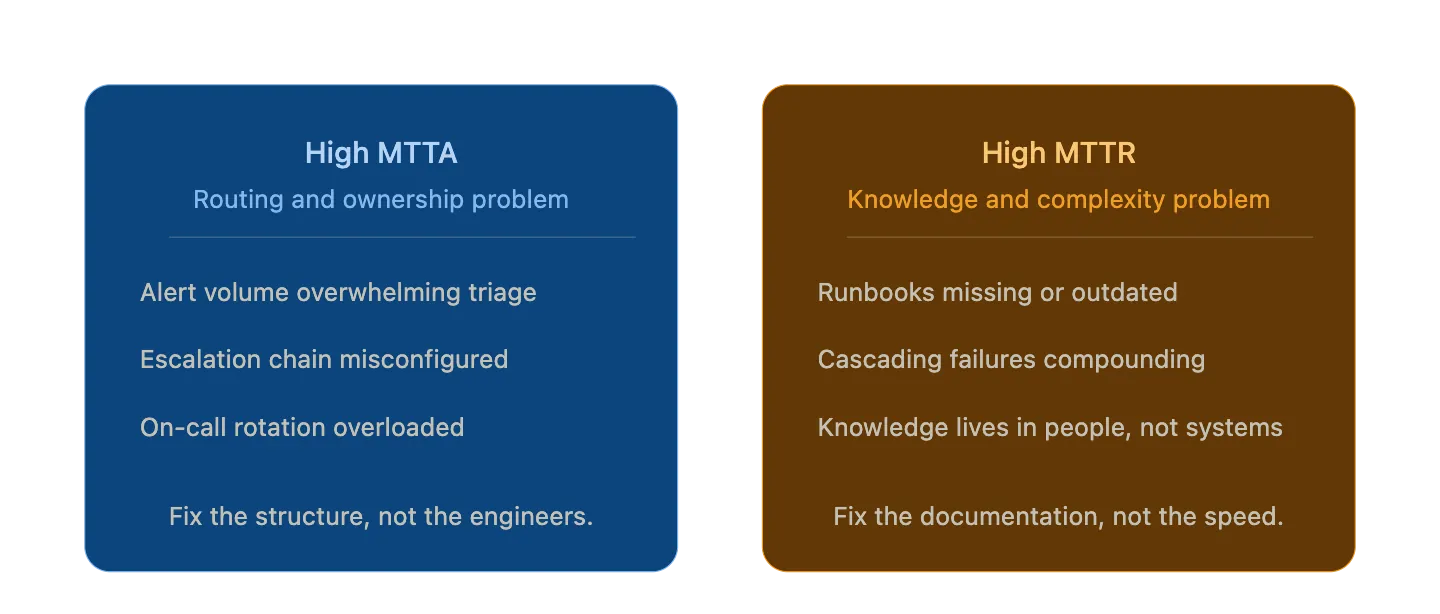
Tracking them together hides this distinction. A team can have excellent MTTA and poor MTTR, or vice versa, and each situation calls for completely different interventions. The number that matters depends entirely on which part of the incident lifecycle you're actually trying to improve.
A team can have excellent MTTA and poor MTTR, or vice versa. Each calls for completely different interventions.
Noisy alerts are a documentation problem, not a monitoring problem.
The instinct when alerts get noisy is to add more filtering, more suppression rules, more layers of triage. Sometimes that's right. More often, noisy alerts are a signal that the system has changed and the alerting rules haven't kept up.
Thresholds set when your infrastructure was a quarter of its current size will fire constantly at today's traffic levels. Engineers learn to recognize them as normal and stop responding with urgency. That's a rational adaptation to a broken signal. It's also how critical alerts get missed.
The fix isn't suppression. It's accuracy. Alerts should fire when something is actually wrong, at thresholds that reflect the system as it exists today. Maintaining that accuracy is ongoing work, not a one-time configuration task. Most teams treat it as the latter.
Alert quality is a form of documentation. It reflects how well your team understands and has described the current state of the system. If your pager is noisy, the system is not misbehaving. It is poorly described.
The best incident response systems are quietly running alongside the engineer on-call — escalating, routing the alert to the right person, spinning up the Slack channel, creating the ticket, pushing comms out. None of that requires the on-call engineer to stop and manage it. It just happens.
That's what good process design actually means in an on-call context. The system handles everything that can be systematized so the human on-call can focus on the one thing it can't: figuring out what's actually wrong and fixing it.
When we got serious about this, the results were measurable. Automating escalation, building routing rules that reliably got the right alert to the right person, and connecting incident response directly to service management so that follow-up tasks didn't slip through. The combination moved our numbers in a direction we're proud of.
36%
Improvement in daily average incident resolution, achieved by automating ownership, routing, and escalation.
None of this is novel in theory. The challenge is that it requires committing to structure at a time when structure feels like overhead. The on-call rotation is already stretched. Writing runbooks is slower than just fixing the thing. Tuning alert thresholds is invisible work with no immediate payoff.
The teams that invest in it anyway are the ones whose on-call engineers are still doing the job five years later. Because the job is manageable.
Fix the ownership. Measure honestly. Build the process so it gets out of your way.

If you’ve made it here, you’re probably thinking of what other options you have to migrate to and ensure your servers/systems stability throughout the migration process. We’ve done the research for you and this blog is all about helping you find a robust solution.

During the second SPARK event in Antwerp, I stood at the back of a training room and watched a customer build a custom integration with our new iPaaS, wiring Xurrent to another system in her stack that had never talked to it before. No services rep doing it for her. No statement of work, no project plan with a kickoff and a go-live date. Just a person with live beta access in her hands, connecting two systems by hand, and finishing it before her coffee went cold. A year ago that would have been a multi-week project with a budget attached. She looked up, a little surprised it had actually worked, and said something I have not stopped thinking about since. She said it just gave her her week back.

Most vendors will tell you ITSM implementation takes six months to a year — but modern, configuration-first platforms have rewritten the math entirely. See what real implementations look like in 2026, and why a long rollout is now a choice, not a given.



.webp)
.webp)






